Process CSV Files in Python Like a Pro: 3 Proven Techniques
Python offers several powerful ways to work with CSV (Comma-Separated Values) files, making data handling efficient and streamlined. In this blogpost, I’ll share 3 simple yet proven techniques to process CSV files in Python:
First things first, let’s define our target: the CSV file
What is a CSV File?
A CSV (Comma-Separated Values) file is a plain text file that stores tabular data in a specific format.
- Tabular Data: This means the data is organized in rows and columns, similar to a spreadsheet.
- Comma Separation: Each value within a row is separated by a comma.
- Plain Text: CSV files are simple text files that can be opened and viewed with any text editor.
Here’s a simple example structure:
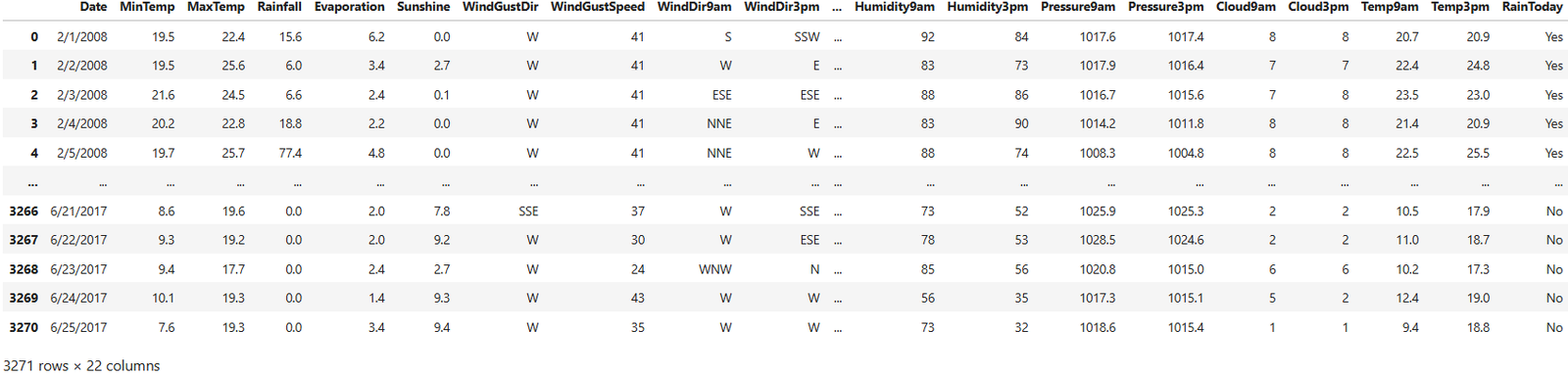
I got this dataset from Kaggle, you can find it here: Weather Data
Key Characteristics of CSV Files:
- Simplicity: Their straightforward structure makes them easy to create, read, and understand.
- Versatility: CSV files are widely used across various applications and platforms.
- Compatibility: They can be easily imported and exported by many software programs, including spreadsheets (like Excel), databases, and programming languages (like Python).
Why are CSV Files Important in Data Science?
CSV files are a fundamental part of data science, as they provide a convenient way to store and share data. Whether you’re working with numbers, text, or a combination of both, CSV files make it easy to import and export data between different tools and systems. In fact, CSV files are widely used in data analysis, machine learning, and data visualization, making them an essential skill for anyone working with data.
Common Uses of CSV Files:
- Data Exchange: Sharing data between different applications and systems.
- Data Storage: Storing and organizing data in a simple and portable format.
- Data Analysis: Importing data into tools for analysis and visualization.
- Machine Learning: Preparing data for machine learning models.
Alright, enough theory! Let’s get our hands dirty and explore how to process CSV files using Python.
3 Techniques to Process CSV Files in Python
In the next section, we’ll explore three easy ways to process CSV files using Python. Whether you’re a beginner or an experienced data scientist, these methods will help you get started with working with CSV files in Python.
For this demonstration, I’ll be working with an Australia Weather Rain dataset.
1: Using the CSV Module
The csv module is a built-in Python library that provides a simple and efficient way to read and write CSV files. Here’s an example of how to use it:
Reading CSV Data:
Import the library:
import csv Open your CSV file:
with open('Weather_Data.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(row)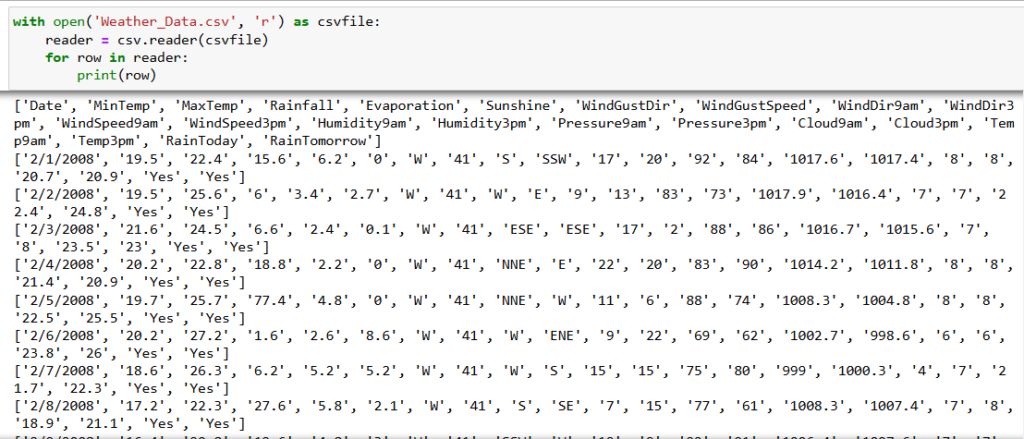
Writing CSV Data:
Here is the example :
import csv
data = [['Name', 'Age', 'City'],
['Alice', '25', 'New York'],
['Bob', '30', 'London']]
with open('output.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)2: Using the Pandas Library
Pandas is a powerful library for data analysis in Python. Its read_csv function provides a convenient way to read CSV files into a DataFrame, which can be easily manipulated and analyzed. Here’s an example of how to use it:
Import the library
import pandas as pdReading CSV Data
# Read a CSV file into a DataFrame
df = pd.read_csv('Weather_Data.csv')
df# Print the first few rows of the DataFrame
print(df.head())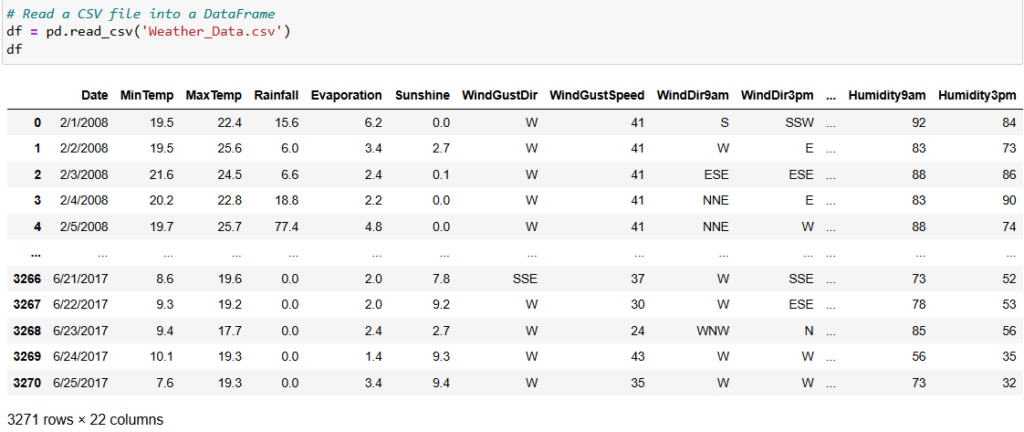
Writing CSV Data:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 22],
'City': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
df.to_csv('output.csv', index=False)3: Using the NumPy Library
NumPy is a library for efficient numerical computation in Python. Its genfromtxt function provides a way to read CSV files into a NumPy array, which can be easily manipulated and analyzed. Here’s an example of how to use NumPy to read a CSV file:
Import the library
import numpy as npReading CSV Data
data = np.genfromtxt('Weather_data.csv', delimiter=',', skip_header=1)
print(data)Here’s an example:
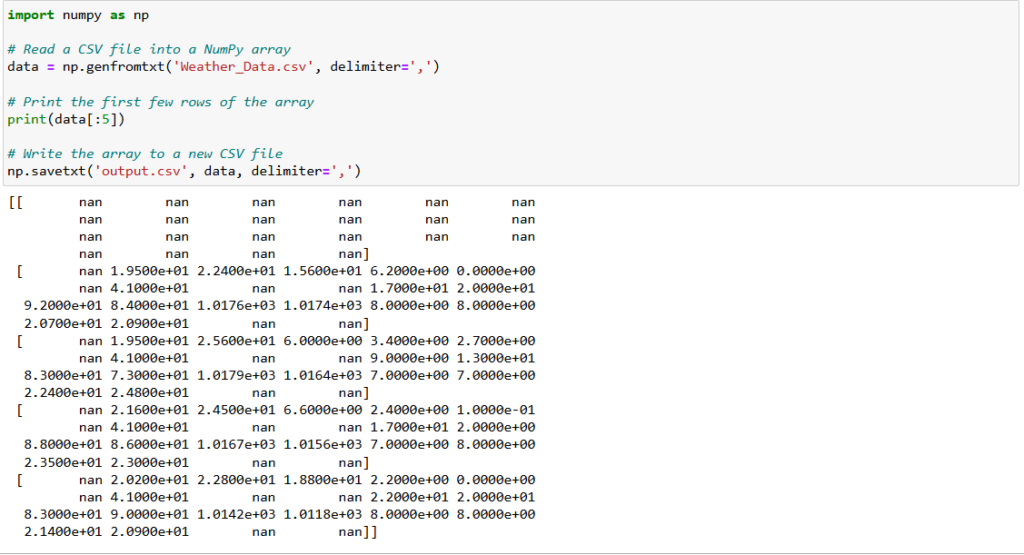
Writing CSV Data:
import numpy as np
data = np.array([['Alice', 25, 'New York'],
['Bob', 30, 'London'],
['Charlie', 22, 'Paris']])
np.savetxt('output.csv', data, delimiter=',', fmt='%s') Selecting the Best Approach
csvmodule: Best for basic read/write operations and when you need fine-grained control over the CSV parsing process.pandaslibrary: Highly recommended for data analysis and manipulation tasks. Offers a wide range of features like data cleaning, filtering, aggregation, and visualization.numpylibrary: Suitable for working with CSV data as arrays, especially when dealing with numerical data for scientific computing or machine learning.
Key Considerations:
- File Handling: Always use the
withstatement when working with files to ensure proper resource management and prevent potential errors. - Data Cleaning: Before any analysis, it’s crucial to clean and prepare your CSV data by handling missing values, removing duplicates, and correcting inconsistencies.
- Performance: For large datasets, consider using optimized libraries like
DaskorVaexthat can handle data in parallel or out-of-core.
In this basic tutorial, we explored the three powerful methods for processing CSV files in Python. By mastering these techniques, you’ll be well-equipped to handle a wide range of data analysis tasks. I encourage you to experiment with these approaches and discover their full potential.
Have you encountered any challenges while working with CSV files? Do you have any other preferred methods? Share your experiences and insights in the comments section below! And don’t forget to share this tutorial with your fellow data enthusiasts!
For expert data analysis and insights, consider hiring me! I can help you unlock the value of your data.
Happy Learning !
